Step-by-Step Guide to Building Blockchain Nodes: Key Considerations and Practical Tips
This post provides a high-level overview for blockchain engineers and beginners looking to set up and operate blockchain nodes. Let's dive in!


Introduction
Greeting builders! In this post, I’ll provide a high-level overview for blockchain engineers and beginners looking to set up and operate blockchain nodes. You will see that breaking up hard parts of the node setup into concrete steps gives better clarity with regard to major processes involved, thus making it easier.
As I go further, I will hopefully be pointing at common challenges along the way and providing practical advice based on real experience. Let's dive in!
The journey to building a reliable node is divided into 7 key steps:
Step 1. Identifying Node Type to Setup
Step 2. Choosing Node Clients
Step 3. Setting up Hardware
Step 4. Downloading & Installing the Clients
Step 5. Client Configuration
Step 6. Synchronization
Step 7. Operation
Step 1. Identifying Node Type to Setup
Prerequisite: Understanding Nodes in a Network
A node is essentially a participant (or 'peer' in P2P networks) within a decentralized blockchain network. Each node operates independently for it’s own purpose, yet communicates with other nodes to follow the protocol ensuring network security and reliability. Functional tasks such as data propagation, transaction validation, consensus building, and blockchain data storage are typically part of the protocol.
You can configure a node to manage all of these tasks or to focus on specific functions depending on your objectives. This determines the node type, which is classified by two primary criteria: their responsibilities and data availability.
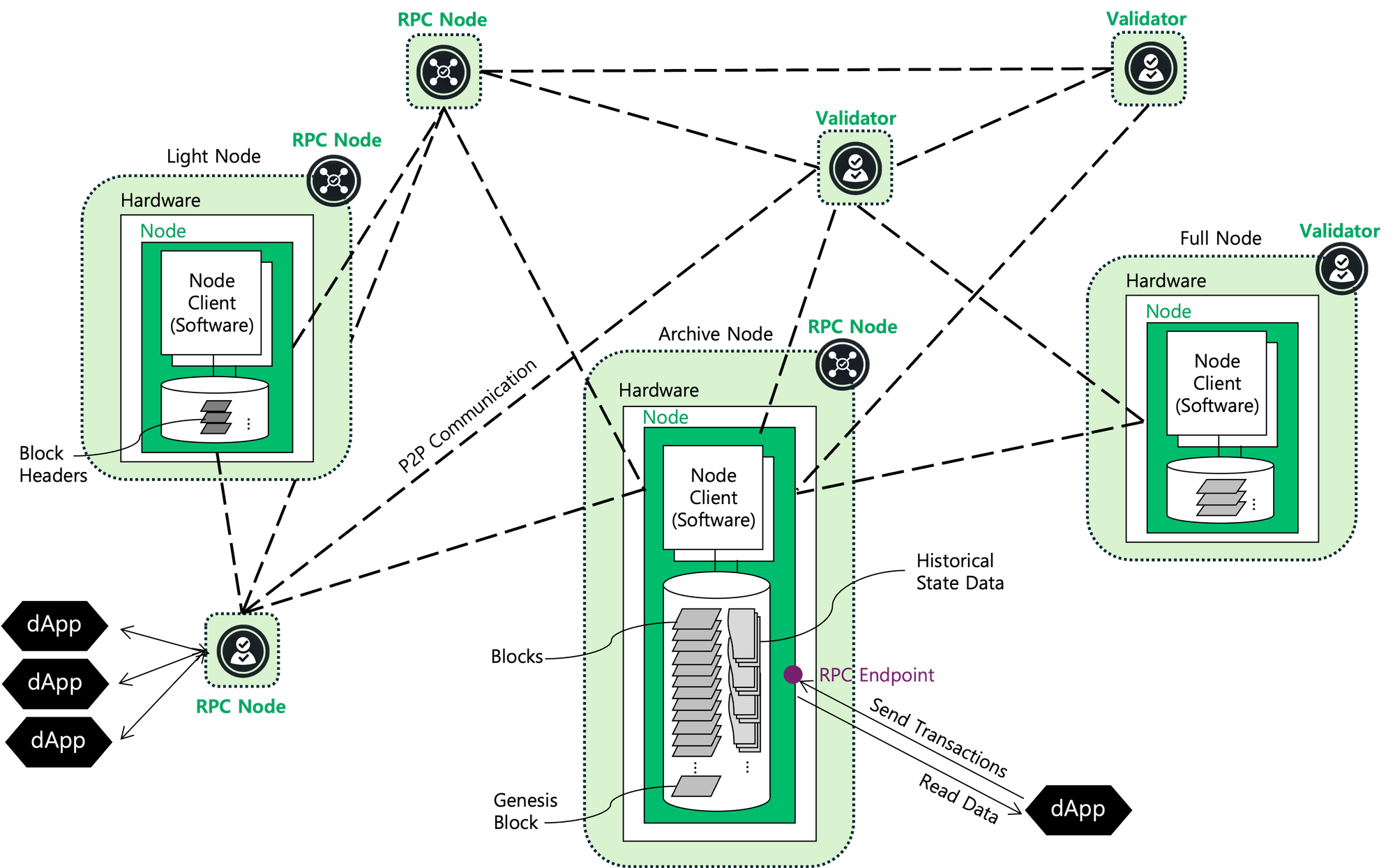
Node Types by Responsibility
- RPC Node: Remote Procedure Call (RPC) nodes specialize in interacting with applications that need to read blockchain states or send transactions.
Best for: Developers or Web3 builders building dApps that interact with the blockchain. - Validator Node: Validator nodes participate in consensus by staking tokens, proposing, and validating new blocks, playing a key role in maintaining network security and consensus.
Best for: Individuals aiming to secure the network and earn rewards. - Seed Node: Seed nodes helps new nodes find peers and connect to the network.
* Typically managed by trusted entities like blockchain foundations.
Node Types by Data Availability
- Full Node: Full node stores the entire blockchain and verifies all transactions and blocks.
* In Ethereum, a full node stores the state of the most recent 128 blocks and removes the order state data.
Best for: Those aiming to fully validate transactions and contribute to network security. - Archive Node: Archive nodes store the full blockchain along with historical state data, enabling the retrieval of past chain states, in addition to the full-node’s functionalities.
Best for: Data analysts or applications requiring historical blockchain data. - Light Node: Light nodes store only block headers and depend on full nodes for transaction validation. They are optimized for faster operation and minimal resource use, making them ideal for users with limited computational resources.
Best for: Those needing basic blockchain interactions with minimal resource requirements. - Pruned Node: Pruned nodes enable selective storage of blockchain data, commonly seen in protocols like Cosmos SDK-based blockchains. Users can configure the number of blocks or states to retain, reducing storage needs while still participating in validation.
Best for: Those requiring flexible data storage with reduced resource needs in supported protocols.
Identify the Node You Need
To simplify things for beginners, think of these two classification systems as not mutually exclusive. Start by identifying your objectives, then select the node type combination that best suits your specific needs. Here are a few examples:
- Full-Validator Node: A node participates in consensus by validating and proposing blocks while storing the entire blockchain, enabling full transaction verification.
- Pruned-Validator Node: A node validates blocks but stores only recent ones, reducing storage while maintaining security.
- Archive-RPC Node: A node serves dApps by storing the full blockchain and historical data, ideal for data-heavy queries.
- Light-RPC Node: A node provides faster, resource-efficient access by storing only block headers and relying on full nodes for verification.
Tips!
If you're setting up a RPC node for building Web3 services, you’ll typically choose between a Full Node and an Archive Node. A key consideration is that archive nodes demand significantly more storage, require deeper technical expertise, and come with higher operational costs compared to full nodes.
For most blockchain development tasks—like building dApps, smart contracts, or interacting with the network—a full node is more than enough. When if your use case involves querying historical blockchain states at specific blocks or tracking state changes over time, an archive node becomes essential.
Step 2. Choosing Node Clients
Prerequisite: Understanding Node In Implementation Layer
Now that we understand what nodes are and their functions, let's look at how they work at the implementation layer. A node is an abstraction representing one or more clients running on a machine. Depending on the network, a node can run a single client or multiple clients. For example, in Ethereum, an execution layer and consensus layer client are separated, both are required for validator use case.
Choose the Right Node Client for a Node
Typically, you have multiple choices of node clients provided by both the protocol foundations and developer communities. This client diversity is crucial for maintaining a resilient decentralized network, as it helps prevent single points of failure and increases security. Each client focuses on different aspects of node operation so choosing the right node client is critical. It directly influences your node’s performance, resource usage, and overall reliability, making the selection process an important part of node setup.
When selecting a node client, consider the following:
- Protocol Compatibility Ensure the client supports the node type and network you’re targeting. For example, Ethereum validators need both an execution layer client (e.g., Geth, Nethermind) and a consensus layer client (e.g., Prysm, Lighthouse).
- Performance and Resource Requirements Node clients vary in terms of memory usage, processing power, and storage needs. For exmaple,Assess your hardware capabilities and choose a client that aligns with your node's resource demands.
- Full or Archive Nodes require clients that handle large amounts of data efficiently. Clients like Besu and Nethermind are designed to work with heavier data loads and may offer optimizations for high storage environments.
- Pruned or Light Nodes can benefit from clients that are optimized for lower resource usage, which provides high performance while using less storage.
- Community Support and DevelopmentChoose a client that has strong community support and active development. An actively maintained client ensures timely updates, bug fixes, and security patches.
- Security and StabilityThe security track record of a node client is crucial, especially if you're operating a Validator Node that directly participates in consensus. Clients with a solid history of handling vulnerabilities should be prioritized. You want a client that is stable and proven to withstand network attacks or bugs.
Step 3. Setting up Hardware
Use a Dedicated Environment
Now it's time to think about hardware to run the clients. While it's possible to run a node client on any device including personal computers, I highly recommend using a dedicated machine or infrastructure. It would significantly boosts your node’s performance and makes ongoing maintenance much easier.
Cloud vs. On-Premise
Cloud platforms like AWS, Google Cloud, or Azure provide reliable uptime and consistent bandwidth, ensuring stable node performance. They excel in scalability, offering seamless on-demand infrastructure scaling, geographical scaling, and storage expansion as blockchain data grows.
The downside of using cloud? It’s pricey. By mid-2024, running only a stable full Ethereum mainnet node on AWS costs $500+ per month, with storage expenses rising as the blockchain expands. For more data-heavy protocols such as Polygon or Arbitrum, these costs can easily double or triple.
Tips!
Q. What does geographical scaling mean and why do I need it?
A. Geographic asymmetry in the decentralized networks can sometimes cause higher latency for distant nodes slowing transaction processing, node synchronization, and consensus participation. If you are building a powerful blockchain infrastructure that will be globally used, deploying across multiple regions helps optimize performance and enhance product resilience against this characteristics.
On-premise setups may lack the flexibility of cloud solutions but offer long-term savings and full control. Running your own node reduces security risks and eliminates trust on third parties, improving both privacy and network resilience. You keep sensitive data in-house, which avoids exposing it to external services. However, it comes with high upfront costs and ongoing maintenance tasks making seamless scaling be complex.
Yes, it’s a trade-off. When choosing between cloud and on-premise setups, it depends on your needs. Cloud platforms offer scalability, minimal maintenance, and flexibility but at a higher cost. On-premise solutions provide long-term savings, full control, and better privacy but require significant upfront investment and maintenance.
Tips!
Start with cloud infrastructure helps optimize hardware and client configurations. As you gain expertise and need to scale, transitioning to an on-premise setup using refined hardwares and packages can be a solid approach.
Hardware Requirements Dependencies
The hardware requirements vary based on the node type, client, and the blockchain protocol.
Node Type-Specific Considerations
The hardware demands for running blockchain nodes can vary greatly depending on the type of node. For instance, full nodes and archive nodes require more CPU power and RAM than light nodes because they perform more complex computational tasks and handle higher volumes of read-write operations. Archive nodes, in particular, can need 2–5 times more storage than full nodes, as they store historical states of the entire blockchain. Here are general hardware guidelines by node type.
- Full Node: 4+ cores of CPU, 16GB+ of RAM, ~2TB of SSD, 50 Mbps
- Archive Node: 6~8+ cores of CPU, 32GB+ of RAM, ~10TB of SSD, 50+ Mbps
- Light Node: 2+ cores, 8GB+ of RAM, ~25 Mbps
These are general guidelines and may vary depending on network activity (i.e., the number of transactions), client configurations, and node optimizations.
Tips!
Based on experience, it's often a good idea to use slightly higher hardware specifications than the official recommendations for running a stable node. This is especially true in cloud environments. In addition to adjusting instance specs, you can optimize node performance by fine-tuning the data storage.
These optimizations and best practices are frequently discussed and updated in each protocol’s developer communities, so make sure to stay active and leverage these resources for the latest insights.
Node Client-Specific Considerations
Different node clients have unique performance characteristics, affecting CPU, RAM, storage, and network requirements. Clients like Erigon prioritize storage efficiency, making it ideal for environments with limited storage(e.g., an Ethereum archive node requires around 3 TB with Erigon, compared to 13.5 TB when using Geth), while Nethermind focuses on high performance, requiring more computational power. The selection of a client should align with your available infrastructure and the specific demands of the blockchain network you're operating. For precise hardware requirements, always refer to the official client documentation to ensure optimal configuration.
Protocol-Specific Considerations
Each blockchain protocol has its architecture and consensus mechanism, which affects the requirements. Protocols like Solana, designed for high throughput, require low-latency transactions with large network bandwidth and huge computational power. In contrast, protocols like Polygon and Avalanche designed for heavy traffic and extremely low transaction fees need larger storage capacities since more transactions will be settled. Arbitrum and Optimism's archive nodes also require large amounts of storage to store the compressed Layer 1 transaction data native in L2 rollups. This is why running multi-chain nodes can be challenging—it requires distinct hardware strategies tailored to the specific needs of each blockchain.
Step 4. Downloading & Installing the Clients
With your hardware ready, it’s time to get hands-on. Let’s proceed by downloading and installing the client of your choice.
Download the Client
To get started, visit the official website or repository of your chosen client. Ensure you download from trusted sources to avoid security risks. You may choose to download the precompiled binaries, docker images, or source code for compilation depending on your setup preferences.
- Precompiled binaries are the fastest option, offering a ready-to-go executable that you can download and install directly for your operating system. It’s the simplest route with minimal configuration, but it limits customization options.
- Docker offers a more streamlined approach, packaging the client and all its dependencies into a container. This avoids system conflicts, making it ideal if you’re running multiple nodes on the same machine. However, Docker adds a slight performance overhead due to containerization.
- Source compilation gives you complete control, allowing you to compile the client from the source code. This method is preferred for advanced users looking to customize configurations or optimize performance, though it requires more technical expertise and can be time-consuming.
Each has its strengths, and the best choice depends on your technical expertise and the level of customization you require for your node setup. Keep in mind that the available options can vary by client, so check the documentation for your chosen client to see which installation methods are supported.
Install the Client
Follow the installation steps provided by the client documentation. This usually involves executing a few commands, with steps varying based on your OS (Linux, macOS, or Windows) and the client itself. If you prefer a containerized setup, most clients offer Docker support to simplify the process. After installation, you can start the client for a test! Be sure to monitor system resources during the initial run to confirm the node is running efficiently. This ensures your hardware can handle the workload as you move to more intensive operations like configuration and synchronization.
Step 5. Client Configuration
After installing your node client, configuring it correctly ensures optimal performance and stability. This step involves setting up network connections, adjusting resource allocations, and tailoring the node’s behavior to fit your specific needs. While the exact configuration will depend on the client and blockchain protocol, the following guidelines cover essential aspects common to most setups.
Target Network and Node Type Selection
- Target Network: Configure the network you’re connecting to, whether it’s the mainnet, testnet, or a specific private chain.
- Node Type: Use client-specific commands to determine whether your node operates as a full, archive, or light node. For instance, in Geth, adding the
-syncmode fullor-syncmode lightdefines the node’s sync type.
Data Directory and Storage Configuration
Choosing the right storage location and configuring how the client manages data are key aspects to avoid performance bottlenecks.
- Data Directory: Specify the location where the blockchain data will be stored. For large datasets like archive nodes, ensure this path is set to a high-performance SSD with enough capacity to handle ongoing blockchain growth.
- Pruning (Optional): For full nodes, you may enable pruning to limit the storage of old blockchain data, reducing the space required by your node.
- Cache Size: Adjusting the cache size can improve the node’s performance. Most clients allow you to allocate more RAM for caching blockchain data, improving sync and validation speeds.
Security and Peer Connections
Configuring security settings is vital to protect your node from potential attacks, especially if you're running a public-facing node or validator.
- Network Security: Ensure that your node operates behind a properly configured firewall to limit unauthorized access. Only necessary ports should be exposed, and internal administrative ports should be closed to external connections.
- Peer Connections: Configure the number of peers that can connect to your node. More peers can increase decentralization and speed up data propagation but also increase resource usage.
- Authentication and Encryption: Implement strong encryption methods like TLS for communication between your node and external systems. For validator nodes, ensure that private keys are securely managed and stored in an offline or hardware-based solution.
Resource Allocation
- CPU and RAM Usage: Clients like Erigon and Geth allow you to set limits on how much CPU and RAM the node can use. Configure these settings based on your hardware capabilities to balance node performance with system stability.
- Network Bandwidth: Ensure that the client’s bandwidth usage aligns with your available network capacity. Validator nodes or high-traffic full nodes may need more bandwidth for consistent performance.
- Storage: Set limits on storage capacity based on your hardware capabilities.
Tips!
The node client may default to settings that exceed your hardware's available resources, leading to failed or unstable operation. It's crucial to allocate resources such as CPU, RAM, and storage properly to ensure your node runs smoothly and reliably.
Backup and Recovery Setup
To ensure your node can recover from crashes or data corruption, configure a backup routine.
- Automatic Backup Scripts: Most clients allow you to configure automatic backups of your node’s data directory. Regular backups will ensure that you can recover your node if necessary.
- Snapshot: For archive nodes, creating periodic snapshots of the blockchain state can save time when restoring from a backup.
Tips!
For quick recovery from unexpected node failures, I recommend creating snapshots regularly. You don’t need full snapshots every time—reduce storage costs by managing multiple snapshots and using incremental snapshots, which store only changes since the last backup.
Step 6. Synchronization
Once your node is configured, the next step is synchronization, where it downloads and verifies blockchain data to ensure it's up-to-date with the network. Full sync mode downloads and verifies all blocks from the genesis block, which can take considerable time—Ethereum full sync might take several weeks depending on your hardware and network.
Fast sync skips the full transaction history and downloads only the most recent blockchain state, catching up by verifying recent blocks. This reduces sync time significantly. Light sync, used by lightweight nodes, downloads only block headers and depends on full nodes for verification, minimizing storage and bandwidth usage. Archive sync, on the other hand, stores the entire blockchain history, requiring the most storage and time to complete.
During the initial sync, data is downloaded and verified for integrity, then written to the node’s storage. Ensure adequate disk space, especially for full or archive nodes.
Tips!
Based on experience, for Polygon or Arbitrum, four times more storage for archive nodes is required than in an Ethereum node. Additionally, ensuring adequate network bandwidth and storage IOPS during the initial sync process is crucial for these transaction-heavy protocols. I also recommend deploying your nodes in regions with low network latency for optimal performance.
Step 7. Operation
Once your node is up and running, maintaining it requires regular operational tasks to ensure it stays healthy, up-to-date, and secure. Effective node management involves continuous monitoring, regular maintenance, and quick response to any network or security events.
Node Health Monitoring
One of the primary ongoing tasks is ensuring your node’s health. Ensure that you have automated scripts or processes to safely shut down and restart the node without risking data corruption. Whether using automated systems or manual monitoring, keeping track of your node’s performance is crucial for reliable operation. Monitoring includes:
- System Resources: Keep an eye on CPU, memory, and disk usage. A resource-heavy node can experience slow performance or downtime if system limits are reached. Use monitoring tools such as Prometheus, Grafana, or Node Exporter to set up alerts for critical metrics.
- Network Connectivity: Ensure your node maintains a stable connection to peers and isn’t isolated from the network. Monitor peer connections, latency, and bandwidth to avoid sync delays. It's essential to include latency monitoring in your metrics to detect and address connectivity issues before they impact node performance.
- RPC Endpoints: If you're running an RPC node for dApp, consistently check the health of the endpoints, ensuring they respond to requests within acceptable times. High traffic can cause socket hang-ups or network proxy issues, making endpoints unavailable. Monitoring for latency and timeouts ****is critical to catching bottlenecks or system overloads, which could lead to degraded performance.
Maintaining monitoring systems adds operational complexity and resource costs. Without effective health checks, your node might encounter performance issues, leaving you vulnerable to network disruptions.
Events Handling
Blockchain networks are dynamic, and your node must be prepared to handle several key events. Regular maintenance includes:
- Re-organizations (Re-orgs): In the event of chain re-orgs, your node may need to discard and reorganize blocks to stay in sync with the correct version of the blockchain. When re-orgs occur, it’s not uncommon for nodes to experience temporary sync pauses lasting several minutes. If you're running a node that services dApps or clients, these synchronization delays could impact the availability or performance of your services. It's crucial to monitor re-org events closely, as any disruptions during this time can have downstream effects on services.
- Hard Forks and Client Updates: Blockchain networks regularly introduce hard forks or protocol upgrades that require node software updates. Hard forks introduce changes to the blockchain’s rules, so it’s crucial to update your client software in advance to avoid being forked off the network. Keep up with developer announcements and security patches.
- Security Events: Be prepared to respond to vulnerabilities in node software or blockchain protocols. Keeping your node’s software updated with security patches is essential, especially if you’re running a validator node.
Ongoing Maintenance Tasks
In addition to responding to network events, several regular tasks are necessary for optimal node operation:
- Data Backup: Regularly back up your node’s data as a snapshot, especially for full and archive nodes. This ensures that you can recover your node in case of hardware failure or data corruption.
- Disk Management: Over time, the blockchain’s size will grow, and you may need to expand storage. Monitor disk usage and allocate additional space as necessary to avoid running out of storage.
- Performance Optimization: Tuning your node’s resource usage (CPU, RAM, storage, bandwidth) ensures it runs efficiently. Regularly review your node’s performance metrics to adjust resource allocation or move to more powerful infrastructure if needed.
Other Considerations
When running blockchain nodes, especially as your operations grow, it’s important to consider scalability and high availability(HA) strategies to ensure resilience and performance. Beyond the initial setup and day-to-day maintenance, scaling your infrastructure can enhance the reliability and capacity of your node pool while reducing the risk of downtime.
Scalability - Node Pool
As network demands increase, a single node may not be sufficient to handle the required load, especially for high-traffic applications or validator operations. A node pool—a group of nodes working together—allows you to distribute the workload across multiple nodes, improving reliability and performance.
- Horizontal Scaling: Add more nodes to distribute traffic and increase capacity. By having several full nodes or validator nodes operating in parallel, you reduce the likelihood of bottlenecks during periods of high activity. This is particularly important for handling API queries or RPC requests for dApp usage.
- Geographic Distribution: Distribute your node pool across multiple geographic locations to ensure redundancy and decrease latency for global users. This also improves resilience by minimizing the risk of all nodes being impacted by regional outages or regulatory issues.
High Availability Options - Multi-client Setup
To enhance resilience, a multi-client setup is a considerable option to avoid dependence on a single client. This approach reduces the risk of downtime or vulnerabilities impacting your node. Just keep in mind that running multiple clients significantly increases hardware and resource demands, as each client requires dedicated processing power, memory, and storage to operate efficiently.
Skip the Complexity: Alternatives to Manual Node Setup
Are you ready to dive into complex, resource-heavy processes? 😅 If not, there are simpler alternatives to streamline node operations, making them much more accessible and scalable for all kinds of projects.
Cloud-Offering Node Solutions
If you'd rather avoid the hassle of manually setting up and managing nodes, cloud platforms now provide managed blockchain services that simplify the whole process. Services like AWS Managed Blockchain, Google Cloud Blockchain, and Azure Blockchain Service allow you to quickly deploy and scale nodes across various blockchains without having to worry about the technical details of configuration, resource allocation, or network management.
In addition to managing nodes, platforms like Google BigQuery take it a step further by offering easy access to blockchain datasets. This means you can query on-chain data directly—ideal for analytics, research, or building data-driven applications—without the need to run a full node yourself.
Node & API Provider
For an even more hands-off experience, Node and API providers make interacting with blockchains a breeze. Instead of just managing the node, these providers handle the heavy lifting by offering ready-to-use APIs that let you query blockchain data, send transactions, or integrate dApps without needing to manage the underlying infrastructure.
Take Nodit (https://nodit.io), for example. Nodit doesn’t just keep your node up-to-date and secure; it also provides pre-processed blockchain data via APIs. Nodit handles all the backend tasks—like node maintenance, updates, and security—while their intuitive APIs give you fast, reliable access to the essential data you need to power your blockchain projects.
Using a solution like this can save a ton of time and headaches. You’ll have fully-managed, scalable nodes at your disposal, plus the ability to quickly gather and work with blockchain data, all without getting bogged down in technical infrastructure. It’s a great option for developers who just want to focus on building.
Conclusion
Setting up and operating a blockchain node is no small feat—it requires careful planning, technical know-how, and ongoing maintenance. Whether you're running a single node or managing a larger infrastructure, the process involves many decisions.
However, with a methodical approach, the complexity becomes manageable, and the rewards are clear: greater control over your interactions with the blockchain, improved privacy, and stronger network resilience. I hope this guide helped clarify the process and gave you the confidence to take the next step.
And remember, there are always alternatives to manual setup if time or resources are a concern. Nodit(https://nodit.io) can take a lot off your plate, allowing you to focus on what matters most: building your product.
In the end, whether you choose to run your nodes manually or rely on third-party services, you’re contributing to strength of the network. Happy building!



