How to Choose an On-Chain Data Service for AI Agents


This research was produced in collaboration with Decipher. For learn more about Nodit’s Web3 infrastructure, please book a meeting here.
Introduction
In previous articles, we looked at the x402 protocol and Nodit. This time, we will explore what factors to consider when choosing an on-chain data service for AI agents.
AI agents are evolving fast. They are no longer just tools that search for information and generate text answers. They are becoming autonomous actors that assess situations on their own and carry out complex tasks. In the Web3 space, for an agent to plan on-chain activities or interact directly with smart contracts on behalf of a user, it needs accurate data about the current state of the blockchain network.
In this article, we look at how the on-chain data service market is changing as we enter a full-blown agent era. Then, we will go over the criteria for choosing a data service built for agents. Finally, we take a closer look at Nodit through practical examples to see how these requirements work in actual use cases.
1. The On-Chain Data Service Market for AI Agents
What Kinds of Tasks Require On-Chain Data?
AI agents are especially strong at automating decisions, actions, and monitoring using on-chain data, particularly in DeFi and risk management. Here are some of the most common use cases:
- Investment and trading automation: Agents analyze on-chain signals like wallet movements, trading volume, and token inflows/outflows to determine when to buy or sell, or to automatically rebalance a portfolio.
- DeFi operations and risk management: Agents monitor loan collateral ratios, liquidation risks, and staking status in real time, and automatically execute actions like swaps, rebalancing, or liquidation responses when needed.
- Security, anomaly detection, and governance: Agents detect unusual fund flows, suspected fraud patterns, and signs of hacks. They also assist in decision-making processes like DAO voting and proposal review.
According to Blockeden, by late 2025, more than 550 Web3 AI agent projects had emerged and the market size exceeded $4.3 billion. On prediction markets like Polymarket, AI agents now account for more than 30% of all transactions. As the scope and complexity of what agents handle grows, the on-chain data infrastructure supporting them becomes increasingly critical.
The On-Chain Data Layers Agents Use
For AI agents to interact with blockchains and use on-chain data, there needs to be supporting infrastructure. There are currently three main types of on-chain data service layers that agents can access: RPC (Remote Procedure Call), which directly connects to blockchain nodes and exchanges raw data; Indexers, which pre-organize the vast raw data on a blockchain so it can be quickly searched and queried; and Web3 Data APIs, which pre-process and refine scattered on-chain data so developers or agents can use it right away.
As agents become more sophisticated, the limits of RPC become clear. When an AI agent has to interpret raw RPC data directly, the volume of information it needs to process becomes enormous, and the computational cost grows accordingly. Indexers that pre-organize data for specific services are useful for deep analysis, but their data is fragmented, which limits flexibility for an agent's general decision-making.
For these reasons, agents in the market today tend to prefer Data APIs in terms of computational and cost efficiency. For example, when querying the token portfolio of a specific wallet, the RPC approach requires hundreds to thousands of individual calls per contract. With a Data API, that same task can be done in a single call. In fact, looking at the AI agent architectures recently built by global infrastructure companies like Covalent and OnFinality, demand is rapidly shifting toward adopting pre-structured multi-chain data APIs instead of raw data.
That said, simply changing how data is accessed does not fully guarantee an agent's autonomous operation. For an agent to call data and handle payments on its own, the underlying infrastructure also needs to be redesigned around the agent.
x402: Enabling Autonomous Payments for Agents
Traditional on-chain data services have mostly relied on a model where users manually obtain an API key, register credit card information, and pay a fixed monthly subscription. But this structure creates unnecessary friction and fixed costs in environments where agents are supposed to judge and act on their own. The technology that emerged to solve this is x402, which supports autonomous payments for agents. As the agent economy expands, x402 is driving meaningful change in both adoption speed and scope.
- Rapid transaction growth and adoption: As the agent economy activates, adoption of the x402 protocol is exploding. As of early 2026, x402 has processed a cumulative total of over 140 million agent-to-agent transactions, with a cumulative transaction volume exceeding $43 million. During peak traffic periods, up to 900,000 payments per week and a daily high of 3.3 million payments are being processed autonomously on-chain — cementing x402 as enterprise-grade infrastructure.
- New business opportunities: Where developers previously had to obtain an API key and prepay a monthly subscription, with an x402-enabled data service, an agent can execute micro-payments of a few cents or less per API call directly through its own wallet. Bain & Company projects that AI agents will account for $30–50 billion in annual US commerce spending by 2030, representing 15–25% of total online retail sales. For on-chain data providers, this means a new business model and revenue opportunity that can scale infinitely in proportion to agent call volume, without relying on human user subscriptions.
- Reshaping the API service market: Many data providers are currently integrating x402 into their infrastructure and transitioning to agent-friendly services. Whether a service offers a flexible billing structure that lets agents autonomously complete everything from data queries to payments, without human approval, is becoming an important adoption criterion.
With the arrival of x402, agents can now handle data calls and payments autonomously within a single workflow. So what conditions does an on-chain data service actually need to meet to support this workflow well? The next section covers the specific criteria for evaluating services suited to the agent environment.
2. Selection Criteria for AI Agents
When an AI agent, or a developer building one, chooses an on-chain data service, the key criteria to consider are as follows.
1. Agent-Friendliness
For an AI agent to effectively use an on-chain data service, two conditions must be met: whether it can access data without restrictions, and whether it can make calls from a variety of environments.
First, the range of data the API provides. Agents perform a wide range of activities through on-chain data: querying assets in a wallet, analyzing token transfer histories, tracking transaction flows, and monitoring block-level events. This enables autonomous decision-making: understanding the on-chain state in real time, executing transactions based on conditions, and providing users with meaningful insights. So agents need easy, chain-agnostic access to a diverse range of data: account balances and transaction history, token transfer and holding status, block data, and internal transactions for tracing fund flows.
Next, the variety of ways to call the API. Depending on their operating environment, agents call services either through an MCP server or as Skills integrated into an AI agent toolkit. MCP (Model Context Protocol) is used in AI agent tool environments like Claude Desktop or Cursor to call APIs through a standardized interface. Skills are used when a coding agent directly learns the API specifications and usage patterns to generate optimized calls. In addition, through LLMs.txt, a documentation format organized so AI agent models can quickly understand a service's structure, agents can familiarize themselves with the service's structure and documentation in advance and plan more accurate API calls. The more calling paths a service supports, the more freely agents can use it regardless of their environment.
2. Reliability and Security
The more autonomously agents conduct economic activity based on on-chain data, the more reliability and security of the infrastructure providing that data becomes a core selection criterion. It is not just about whether the API runs smoothly. You need to ask whether this is infrastructure that institutions can trust and rely on.
The starting point is compliance certification. For an agent to operate within financial institutions or enterprise environments, the infrastructure itself must meet international standards. SOC 2 Type II certification independently verifies actual operational levels across five trust principles: security, availability, processing integrity, confidentiality, and privacy. Unlike Type I, which only evaluates design at a specific point in time, Type II proves that controls have been operating effectively over a period of time. This makes it more than just a certification; it serves as an indicator of operational maturity. As the scale of transactions agents handle grows and their outcomes affect real assets, the significance of this kind of certification only increases.
Beyond that, institutional references matter. It is important to know whether the infrastructure is actually being used by institutions that handle large-scale on-chain transactions, such as exchanges and financial firms. The fact that it is handling institutional-grade traffic in real production environments simultaneously proves both performance and stability. Verified references serve as evidence that the infrastructure will not crack regardless of the scale of task the agent handles. Especially as agents become deeply integrated into financial workflows, infrastructure failure can go beyond a simple service outage and lead to real losses. In that context, institutional references function not as marketing material but as proof of real-world validation.
3. Billing Flexibility
When choosing an on-chain data service, pricing structure is not simply a matter of which is cheapest. The key is whether it can flexibly respond to an agent's usage patterns.
Traditional subscription models are inefficient in agent environments. You pay the same fee every month regardless of how much you actually use, and you have to register a payment method like a credit card in advance to access paid plans. In environments where agents are meant to operate autonomously, this structure creates unnecessary fixed costs and onboarding friction. This is where the significance of payment rails like x402 becomes clear. Agents can access services with just a wallet, no API key or account registration needed. When credits run out, payments are made automatically without human approval before work resumes.
Furthermore, agents work very differently from one another. Some query data intermittently, while others make high-frequency, high-volume API calls. To handle these varied usage patterns, you need more than a single billing method. You need a range of billing models you can choose from based on the situation. The main options are pay-per-request, credit-based, and subscription. Pay-per-request charges you each time a call is made. Credit-based lets you pre-load USDC that is instantly deducted off-chain per call. Subscription is a simple monthly flat-rate plan. The more flexibly these billing models can be chosen and combined based on workflow, the more a service ensures end-to-end workflow completeness in autonomous agent environments.
3. Hands-on with Nodit: Testing the Criteria in Practice
We took the three criteria outlined above, agent-friendliness, reliability and security, and billing flexibility, and checked firsthand how the Nodit service meets them.
On the reliability and security front, Nodit became the first in the Korean blockchain industry to obtain SOC 2 Type II certification in January 2026. Its client base includes domestic and international digital asset exchanges, financial institutions, and gaming companies that handle large-scale on-chain transactions.
For the other two criteria, we connected Nodit MCP to Codex and reviewed them directly. The test was structured in four stages: starting with querying wallet-held assets via x402, then querying recent transaction activity for the same address via Nodit MCP, visualizing the results, and finally generating a draft DeFi strategy.
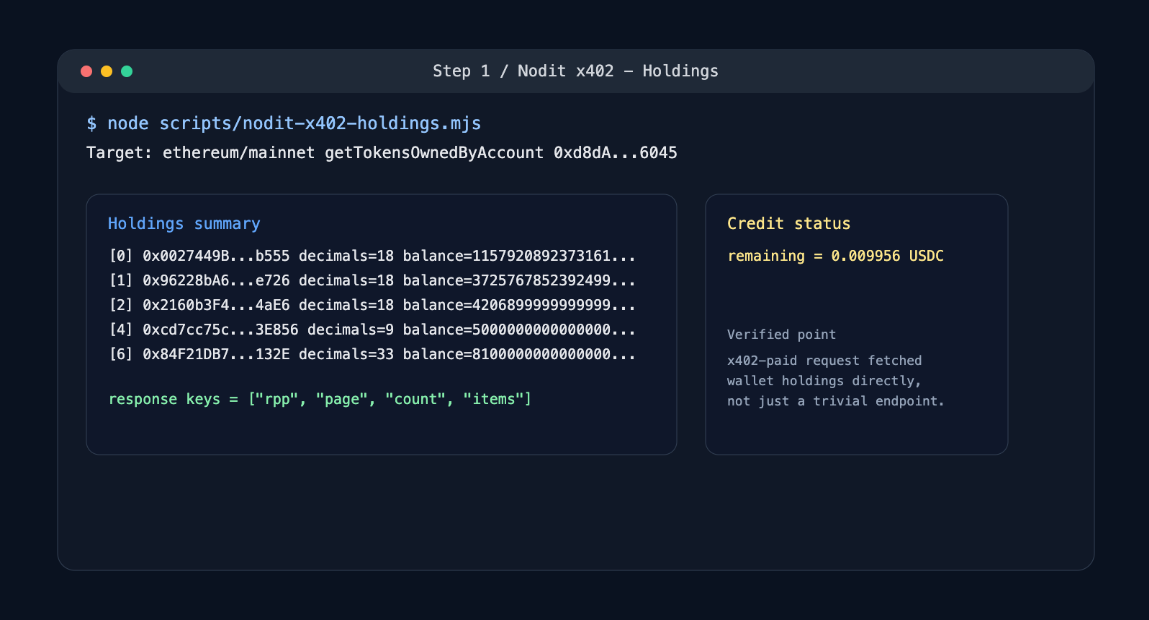
Step 1: Querying Wallet Assets via x402
In the first step, we looked at two things: whether we could query on-chain data using only a wallet-based payment without signing up or obtaining an API key, and whether the billing model could flexibly adapt to usage patterns. We prepared a Base mainnet wallet and called the API to query the list of tokens held by a specific account using Nodit's x402 credit method.
🔎About Nodit
Nodit is an enterprise-grade Web3 platform that provides reliable node and consistent data infrastructure to support the scaling of decentralized applications in a multi chain environment. The core technology of Nodit is a robust data pipeline that performs the crawling, indexing, storing, and processing of blockchain data, along with a dependable node operation service. Through its new Validator as a Service (VaaS) offering, Nodit delivers secure, transparent, and compliant validator operations that ensure stability, performance visibility, and regulatory assurance.
By utilizing processed blockchain data, developers and enterprises can achieve seamless on chain and off chain integration, advanced analytics, comprehensive visualization, and artificial intelligence modeling to build outstanding Web3 products.



![[DataShare Insight] The Hidden Cost of Maintaining Onchain Data Infrastructure](https://storage.ghost.io/c/00/e4/00e497ca-82e8-447b-9af3-b700db69ca26/content/images/size/w600/2026/06/Group-A-_CEX_-Blog-Thumbnail.png)