Nodit Datashare Now Supports Solana


One of the few providers worldwide offering warehouse-native Solana delivery for institutional teams.
TL; DR
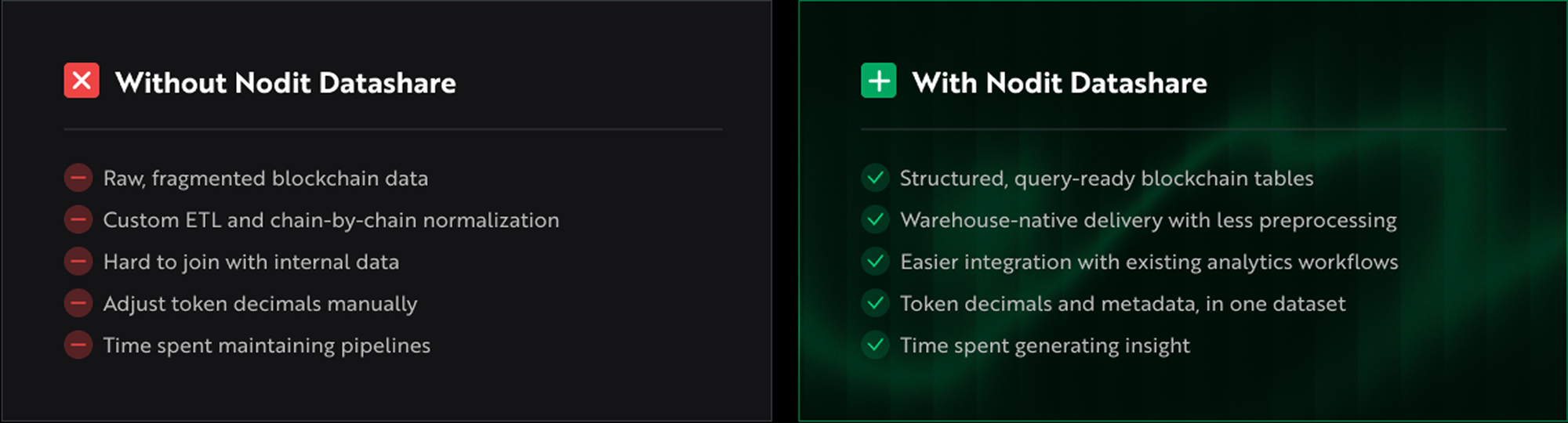
- Solana data is now available on Nodit Datashare for institutional and operational use cases
- Raw blockchain data requires normalization before it is usable in any analytical context
- Nodit Datashare now supports Solana — one of very few providers globally offering warehouse-native Solana data delivery
- Early access is open
Solana is being evaluated as infrastructure, not just as an asset
Institutional interest in Solana has grown steadily — not because of speculation, but because the network's operational profile is increasingly relevant to finance and compliance teams. Sub-second finality, consistently low base fees, and a transaction volume that now exceeds 70 million per day make it a credible settlement and payments layer. The data, however, tells a more complicated story about what it actually takes to work with it analytically.
The data exists. Using it is another matter.
At 70 million transactions per day, the raw data is not the problem. What sits inside each transaction is, and what that means differs by team.
1.For a compliance officer producing an audit trail
The issue is immediately practical. Failed transactions still appear in the ledger and still carry fee charges. A transaction that never executed is indistinguishable from one that did, until someone builds the logic to separate them. Certifying a reporting period without resolving that ambiguity is not something an audit function can accept.
2.For a treasury or finance team
The problem is in the fee data itself. Solana charges two components on every transaction: a base fee per signature and a prioritization fee calculated from compute unit price and limit. That prioritization fee is not stable — during high-demand events it can spike by orders of magnitude from baseline. Both components are charged whether the transaction succeeds or fails. Recording fee spend as a line item requires knowing which transactions failed, what the priority fee was at the time, and how much of that fee was burned versus paid to validators. None of that is surfaced directly.
3.For a product or growth analyst
The first obstacle is that raw transaction counts are unreliable. With a network failure rate of around 20%, any engagement metric built on unfiltered transaction data overstates actual activity by a meaningful margin. Token decimal normalization has to happen before any cohort analysis is meaningful. Joining onchain wallet behavior with internal user records requires a normalization layer that most teams end up building from scratch.
4.For a data engineer
All of the above arrives as a pre-requisite before any business logic is written. Building a Solana pipeline means solving fee structure, failure filtering, decimal normalization, and metadata enrichment first. The pipeline then needs ongoing maintenance as network conditions shift — work that competes directly with the analytical roadmap.
Before any of this resolves, someone has already committed weeks to it. For most teams, that cost stays invisible until the pipeline breaks or the reporting deadline arrives.
Why this is a structural problem, not a tooling one
The difficulty is not that the right API has not been found yet. Each of the problems described above, including failed transaction filtering, fee component reconciliation, decimal normalization, and metadata enrichment, requires an additional layer of interpretation that sits between raw chain output and the structured formats expected by institutional systems.
This is not a gap that a better RPC endpoint closes. The data, as it comes off the chain, is structured for execution, not for analysis. Research on the Solana network found a transaction failure rate of around 20%, compared to roughly 0.1% on Ethereum. Every team that approaches Solana analytically encounters this and builds their own solution. The same problem is solved repeatedly, in different ways, with different levels of completeness.
That repetition is the structural signal. The normalization layer is not optional infrastructure — it is a prerequisite for any institutional workflow, and the cost of building it privately is one that every team currently absorbs before they can start. And yet, despite how consistently this problem appears, the infrastructure to solve it at scale remains rare.
The another problem: The Limited Availability of Warehouse-Ready Solana Data
Solana processes over 70 million transactions per day as mentioned above. Each one carries a two-component fee structure, a transaction status that requires interpretation, and token metadata that needs normalization before it is usable.
At that volume, the infrastructure required to process, normalize, and deliver that data in a warehouse-ready format is significant. Based on our internal research, the number of providers that have built this globally can be counted on one hand like, Helius, QuickNode, Dune, Google Cloud BigQuery among them. Nodit Datashare is one of the few providers and is designed for operational, compliance, and finance workflows that institutional teams run in private environments, unlike public datasets built for developer access.
What Nodit Datashare Brings to Your Warehouse
Nodit Datashare delivers structured Solana datasets directly into existing data warehouses and lakehouse environments. Rather than pulling from fragmented API endpoints and rebuilding normalization logic internally, teams receive data that is already prepared for querying. The normalization work, including fees, metadata, transaction status, and decimal handling, is resolved at the data layer so analysts and engineers can start from a clean foundation instead of raw node responses.
The distance between chain activity and a query a finance or compliance team can run against their own internal records is the problem Datashare is designed to close.
Built for operational workflows
Data arrives as structured tables with fees, transaction status, and token metadata already processed. Historical coverage is maintained so reporting periods can be reconstructed without re-querying live chain state. There is no ETL pipeline to build, no normalization logic to maintain.
The use cases are operational, not exploratory. Compliance functions need reproducible datasets that join cleanly against internal records. Treasury teams need fee data that is already reconciled. Product teams need wallet activity clean enough to feed directly into existing models. Data teams need a stable foundation for dashboards and downstream pipelines — without the maintenance overhead competing with their roadmap.
What teams working with Nodit Datashare are finding
Data team works across the full stack of onchain analytics for one of top tier exchanges in the world described the gap directly:
"Built for teams that need more than raw RPC responses: analytics, risk, finance, compliance, and product operations."
When an exchange-level data team identifies the limitation in the same terms as institutional finance and compliance teams, it signals something structural — not a tooling preference, but a category of infrastructure that the existing API ecosystem was not designed to fill.
Apply for the Early access
If your team is currently pulling Solana data through RPC calls, patching failed transactions manually, or waiting on an internal pipeline build before analysis can start — that is exactly the situation this program is designed for.
We are reviewing applications from data engineering, operations, finance, compliance, and product teams with a concrete Solana use case. The evaluation is straightforward: tell us what your team is trying to do with Solana data and what your current stack looks like. We will come back to you with a clear answer on fit.
This is not a sales process. It is a working session to see if the data we deliver matches the problem you are solving.
What Comes Next for Institutional Solana Data on Nodit
For institutional teams working with blockchain data, the constraint has shifted from access to time-to-usability within existing systems. The ability to move from raw data to operational insight is now the defining requirement.
Solana Datashare represents a step in addressing this requirement, with continued expansion planned across data capabilities and supporting infrastructure. This includes broader dataset coverage, deeper historical and transactional context, and additional data products aligned with the operational, reporting, and compliance needs of finance and data teams.
As institutional adoption of Solana expands across settlement, reporting, and analytics workflows, the infrastructure supporting these use cases will continue to evolve in parallel.
Changes in data requirements over time are expected. As workflows mature, the underlying data layer must adapt accordingly, reducing internal overhead and supporting more advanced operational use cases.
🔎About Nodit
Nodit is an enterprise-grade Web3 platform that provides reliable node and consistent data infrastructure to support the scaling of decentralized applications in a multi chain environment. The core technology of Nodit is a robust data pipeline that performs the crawling, indexing, storing, and processing of blockchain data, along with a dependable node operation service. Through its new Validator as a Service (VaaS) offering, Nodit delivers secure, transparent, and compliant validator operations that ensure stability, performance visibility, and regulatory assurance.
By utilizing processed blockchain data, developers and enterprises can achieve seamless on chain and off chain integration, advanced analytics, comprehensive visualization, and artificial intelligence modeling to build outstanding Web3 products.



![[DataShare Insight] The Hidden Cost of Maintaining Onchain Data Infrastructure](https://storage.ghost.io/c/00/e4/00e497ca-82e8-447b-9af3-b700db69ca26/content/images/size/w600/2026/06/Group-A-_CEX_-Blog-Thumbnail.png)